

















































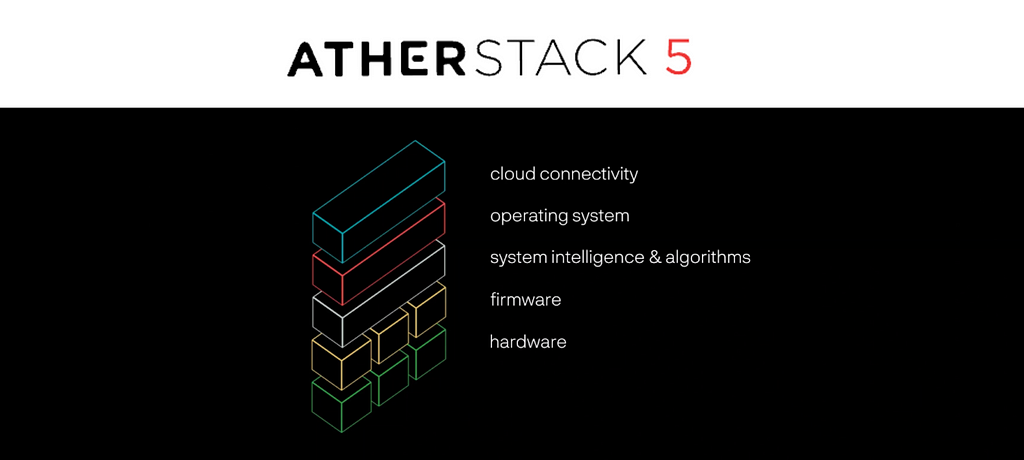
The Ather Dataverse
At Ather, we base our decisions on decoding and genuinely understanding the poetry that is data.

Data is like good poetry; most people who encounter it will never know its true meaning.
To help you understand this, let’s consider a data packet travelling from one of the several sensors we have on the vehicle through AtherStack, our tech stack. A data packet contains information from the sensors along with knowledge of the sensor’s location and timing.
Hardware to Firmware
In an EV, the battery’s voltage is used to monitor the system’s stability and compute the State of Charge (SoC) of the battery pack. This article on BMS models at Ather, by our Chief Engineer, Shivaram NV, describes in great detail how we arrive at the parameters like the SoC and how decisions and insights are generated at this early stage of a data packet’s journey.
Firmware to OS
It’s less about how much information the data packet has than it is about how the data is used. This is where information becomes wisdom. Our data packet is growing!
The firmware and the OS layer communicate over the Controller Area Network (CAN bus). Think of it as the vehicle’s nervous system, transmitting information to and from its various components.
The CAN enables many services that this SoC packet encounters in its path to the OS. Here’s how:
1. The Gatekeepers: Vehicle Core and DI Engine
In the way that Heimdall watches over the realms, we need a service that always knows everything happening in the vehicle. We call this watchful eye the Vehicle Core (VC). The VC performs many functions, from parsing data to computing some essential metrics displayed on the dashboard, such as efficiency, average speed, trip distance, etc., and communicating data to all the other upstream services. Speaking of communication, learn more here about the inter-process communication in an Ather.
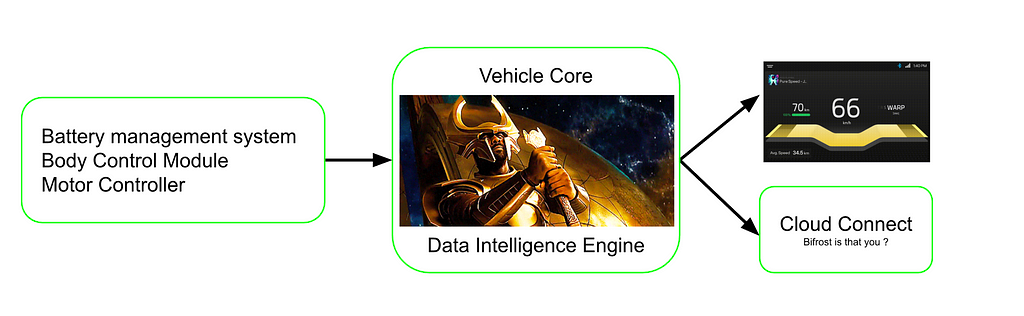
2. The Data Intelligence (DI) Engine
The intelligence layer that runs a slew of algorithms to perform features like the auto-indicator off, theft/tow detection, range prediction, etc., is called the DI Engine. The estimated range displayed on the dashboard is also computed based on the SoC. The DI Engine is exciting and important enough to merit another article.
Once the SoC data reaches the OS layer, it gets parsed to a usable form that multiple applications can read. The DI Engine then computes the user-facing SoC from the BMS-generated SoC based on factors like the generation of the vehicle and the cell type. It passes this information to the dashboard and the Cloud Connect module.
3. Human Machine Interface (HMI) Dashboard
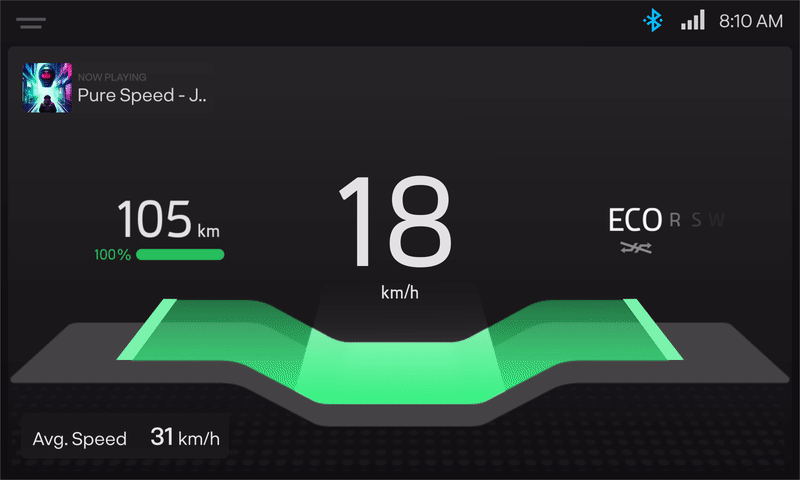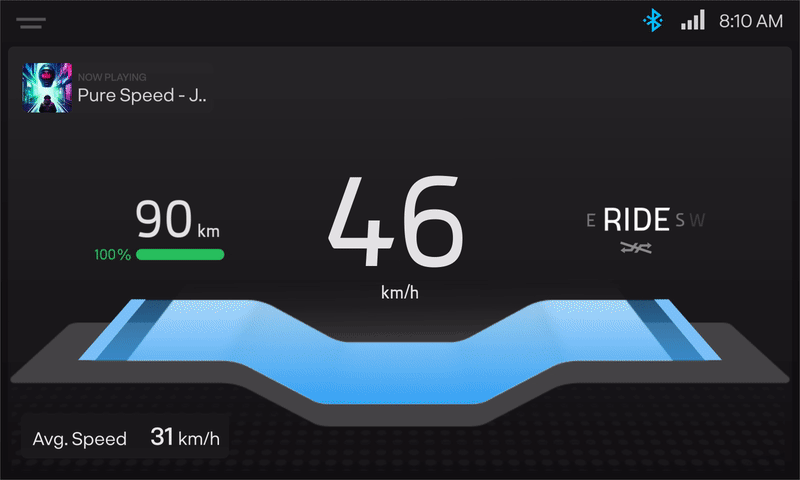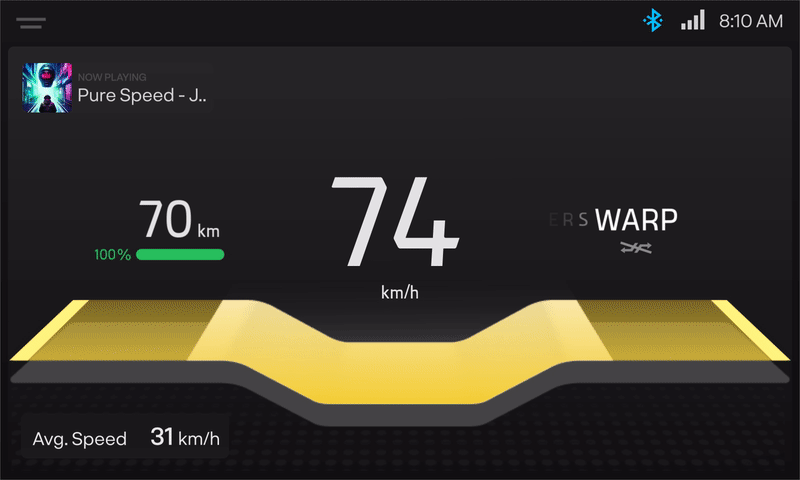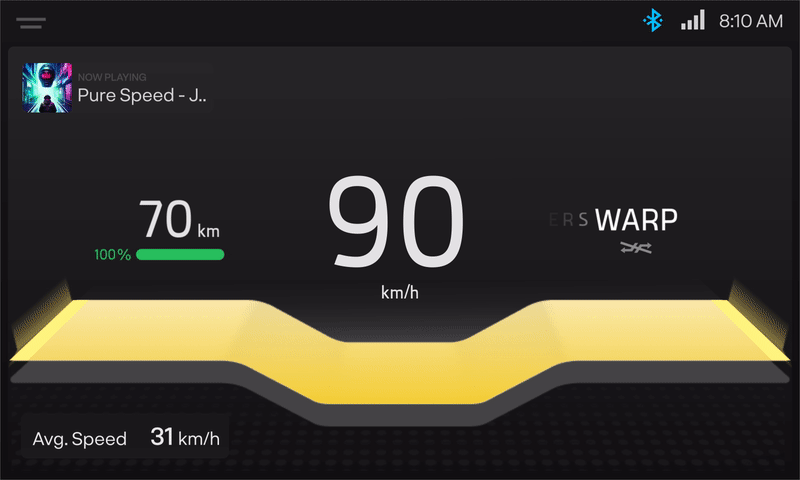
The HMI is where the magic of intelligent visualisation comes into the picture, where the data takes shape into information. From running the only Vector-based map on a two-wheeler to enabling services such as ‘Send to Scooter’ (receive location details sent from the mobile app), Tyre Pressure Monitoring System, and Over-The-Air updates (OTA), the HMI does all the hard work so that the users don’t have to. More on this soon from the magicians!
4. Cloud Connect Module
What good is a connected vehicle without communication to the cobbled webs of the internet? As the name suggests, Cloud Connect connects the vehicle to the cloud. It collects the information sent by vehicle core buffers and transmits it to the MQTT broker. But what if there is no internet connectivity? Will the data be lost forever? Is this the end of life for our data packet? Fear not; our lightweight service written in Rust saves the data locally until it receives an acknowledgement from the cloud that the data packet has arrived safely.
Our data packet has entered the world of Big Data, where its journey will get more interesting!
Big Data Engineering at Ather
The SoC data packet now joins the 150 billion messages we receive from our fleet of 1.6 lakh vehicles daily. The next important question is this. How can data that is merely 0.00000000066% of the total volume of ALL the vehicle data we receive be of any value to the user or the company? Well, the human body does a billion things every day, all the time. But we still need to know when our eyes dry and need blinking.
I am going to oversimplify the entire pipeline here for ease of understanding. The Ather Stack 5.0 includes services built over Kafka, Java, Kubernetes, Spark, Clickhouse, Postgres, MongoDB, Hive, Node JS, Elasticsearch, Golang, Airflow, etc.
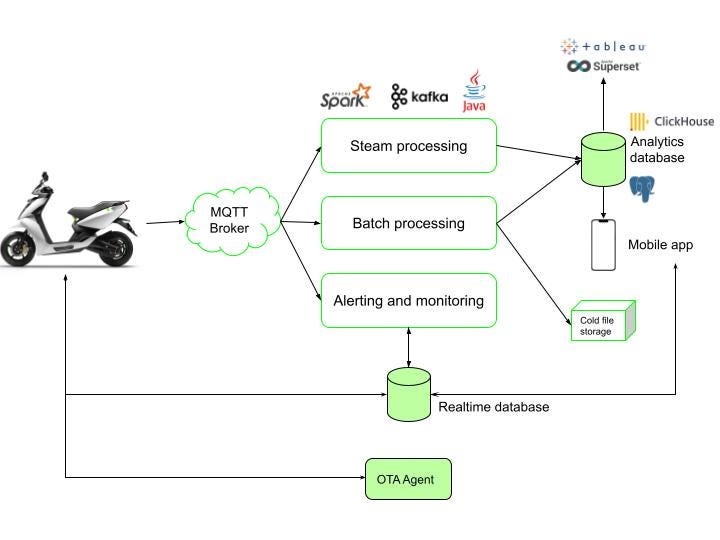
Real-time Stream Processing
One of the most important and arguably the most complex parts of maintaining a connected vehicle ecosystem is the real-time processing pipeline because it has to process 5 Million records/second (during peak hours) in near real-time latency while worrying about process redundancy and fail-safes in the event of a crash. It enables our scooters to do things like critical alert monitoring, anomaly detection, and also helps us build user-facing applications like Ride Stories, Find My Scooter, etc. While most of the computation for these features happens on the vehicle itself, the services running on the cloud make the final decisions. This data is fed into our high-performance databases like Elasticsearch, Postgres, Clickhouse, and Firebase.
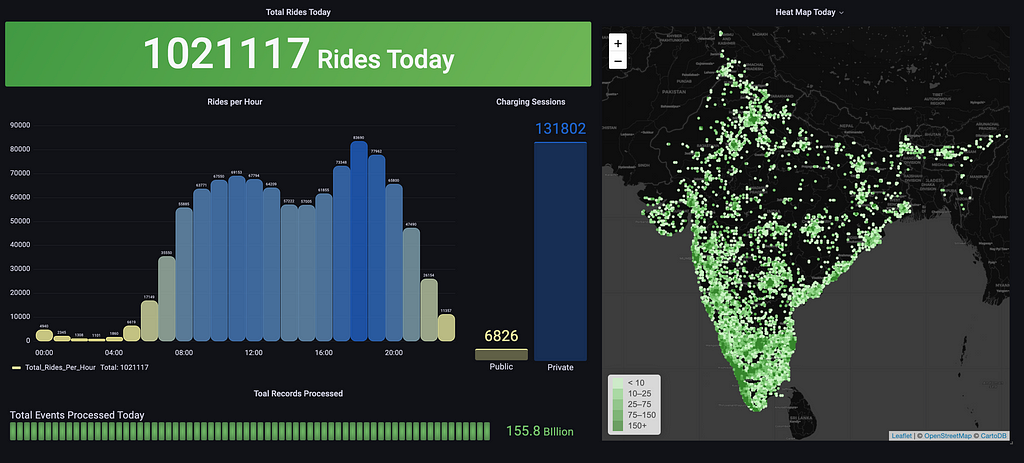
This is how our SoC (State of Charge) packet gets used to display the real-time SoC of the vehicle on the mobile app and compute ride stats that the rider can rely on. The pipeline also enables us to send notifications on the charging status on the mobile app. We want our riders to have the Ather experience at their fingertips.
Batch Processing
All information is not required in real-time, and some information extraction can be batched and processed later at fixed intervals or on demand. The batch processing framework allows us to compute metrics that are not required in real-time but are super critical in the engineering and product decisions at Ather. This framework processes 150 billion messages daily, corresponding to about two terabytes of data, and computes 250+ metrics. These metrics are helpful for our Engineering teams in our endeavour to build a continuously improving vehicle.
At this stage, the SoC gets to computing engineering metrics like cell imbalance, the State of Health (of the battery), etc. We also run algorithms to study the charging patterns amongst Ather owners to draw the roadmap for features like smart charging that will contribute to extending battery life.
We also take great care to ensure data security and privacy. Any personal identifiers (such as names, addresses), and other relevant sensitive details are masked to ensure that the democratised data can be freely used while preserving our customers’ privacy.
Data Warehouse
Maintaining a highly accessible and cost-efficient data warehouse is critical to any Big Data framework. This is where frameworks like Hive and Spark excel. Using a file format like Parquet lets us take advantage of features like bucking, partitioning, and column pruning to obtain insights from the petabytes of raw data we have in the warehouse. All the stored data is stripped of sensitive information, and unique identifiers are masked to maintain anonymity.
Here, the SoC packet comes to the final leg of its journey. The data packet is now a wise old being, having been through the whole of the Ather Stack and having lived a good life providing information and insights to multiple stakeholders. It will rest peacefully along with the Petabytes of data in our ever-growing warehouse until a curious person from our data science team wishes to call upon our protagonist for one of their analyses, and its journey could start over again.
What’s brewing in our dataverse, you ask? Predictive maintenance, anomaly detection, advanced ride stories, smarter ride modes, and more. Stay tuned!
The Ather Dataverse was originally published in Ather Energy on Medium, where people are continuing the conversation by highlighting and responding to this story.
What's Your Reaction?












